Текст моего выступления на внутрикорпоративной мини-конференции.
Сначала скажу, что такое функциональное программирование. Что это такое вообще, можно узнать в Википедии, в SICP (там его называют просто - программирование) или у товарища Одерского в курсе Functional Programming Principles with Scala.
Я же хочу рассказать о том, чем меня цепляет функциональное программирование. И это одна довольно простая вещь. В привычном нам процедурном программировании, описывая алгоритм, мы отвечали на вопрос “как?” Как найти сумму? Как отсортировать массив?
Например, чтобы найти сумму элементов массива, нужно создать счётчик, инициализировать его нулём, пройтись по всему массиву, увеличивая счётчик на значение каждого элемента и вернуть этот счётчик.
def sum(list):
result = 0
for element in list:
result = result + element
return result
result = 0
for element in list:
result = result + element
return result
Я намеренно не использую здесь возможности Питона написать это функционально. Фактически, это псевдокод на почти любом алгоритмическом языке программирования.
Важно здесь то, что код фактически повторяет то, что я сказал выше - “чтобы найти сумму...”
В функциональном программировании, описывая алгоритм, мы отвечаем на вопрос “что?” Что такое сумма? Что такое отсортированный массив?
Например, сумма пустого массива - это ноль. Сумма непустого массива - это первый элемент плюс сумма массива, составленного из остальных элементов.
sum' [] = 0
sum' (x:xs) = x + sum' xs
sum' (x:xs) = x + sum' xs
Опять-таки, этот код фактически повторяет то, что я сказал.
Я проиллюстрирую это ещё раз. Процедурная быстрая сортировка:
public static <E extends Comparable super E>> List<E> quickSort(List<E> arr) {
if (arr.size() <= 1)
return arr;
E pivot = arr.getFirst();
List<E> less = new LinkedList<E>();
List<E> pivotList = new LinkedList<E>();
List<E> more = new LinkedList<E>();
for (E i: arr) {
if (i.compareTo(pivot) < 0)
less.add(i);
else if (i.compareTo(pivot) > 0)
more.add(i);
else
pivotList.add(i);
}
less = quickSort(less);
more = quickSort(more);
less.addAll(pivotList);
less.addAll(more);
return less;
}
if (arr.size() <= 1)
return arr;
E pivot = arr.getFirst();
List<E> less = new LinkedList<E>();
List<E> pivotList = new LinkedList<E>();
List<E> more = new LinkedList<E>();
for (E i: arr) {
if (i.compareTo(pivot) < 0)
less.add(i);
else if (i.compareTo(pivot) > 0)
more.add(i);
else
pivotList.add(i);
}
less = quickSort(less);
more = quickSort(more);
less.addAll(pivotList);
less.addAll(more);
return less;
}
Функциональная быстрая сортировка:
def qsort[T <% Ordered[T]](list:List[T]):List[T] = {
list match {
case Nil => Nil
case x::xs =>
val (before,after) = xs partition (_ < x)
qsort(before) ++ (x :: qsort(after))
}
}
list match {
case Nil => Nil
case x::xs =>
val (before,after) = xs partition (_ < x)
qsort(before) ++ (x :: qsort(after))
}
}
Говорят, что функциональное программирование - это объяснение того, что вам нужно, математику. А императивное - это объяснение того, что вам нужно, идиоту.
Лирическое отступление. Рекурсия. Принято считать неотъемлемой частью функциональной парадигмы такую штуку, как оптимизация хвостового рекурсивного вызова. Без него в ряде случаев будет порождаться ненужно рекурсивный процесс, что будет приводить к падению производительности, переполнению стека и прочим радостям жизни.
Однако я считаю, что можно писать в функциональной парадигме и без оптимизации хвостового вызова, ничего в ней не теряя. Любой чистый алгоритм, описываемый итеративным процессом, можно описать с помощью fold (reduce, inject... как вам нравится). И если в глубинах языка описан fold, порождающий итеративный процесс, то можно во всём положиться на него. Собственно, познакомившись с fold вы, скорее всего, и будете так поступать. Сумма, записанная с помощью fold, выглядит замечательно:
sum(L) ->
lists:foldl(fun(X, Sum) -> X + Sum end, 0, L).
lists:foldl(fun(X, Sum) -> X + Sum end, 0, L).
Хотя, конечно, фича оптимизации хвостового вызова очень полезна.
Однако, вернёмся к теме. Чем так хорошо функциональное программирование?
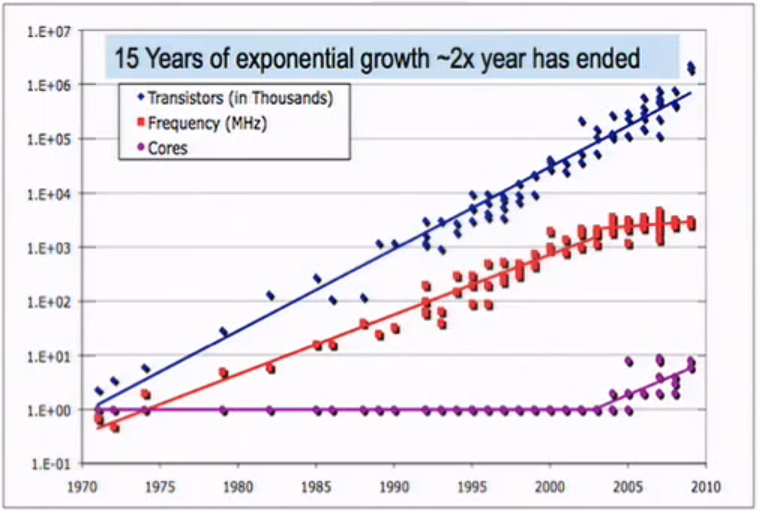
Закон Мура перестал выполняться за счёт количества мегагерц и стал выполняться за счёт количества мега-ядер. Огромных массивов данных требует горизонтального масштабирования алгоритмов их обработки.
Так или иначе, это коснётся каждого из нас. Потому что прекратился рост тактовой частоты одного ядра, а несколько ядер - это не обязательно в несколько раз быстрее.
И хотя нам бы возможно хотелось, чтобы просто продолжался рост тактовой частоты, мы не просили ни многоядерности, ни паралеллизма, но те процессоры, что делают сейчас - это единственное, чего нам следует ожидать в ближайшем будущем. И чтобы освоить предлагаемые мощности, нужно сделать параллельное программирование доступным. А то и популярным.
Здесь есть два близких, но разных аспекта - параллельные вычисления и конкурентные вычисления. Параллельные вычисления - это как сделать так, чтобы программа выполнялась быстрее на параллельном железе. Но она могла бы с тем же успехом работать и в одном потоке - мы просто хотим, чтобы это было быстрее.
Конкурентные вычисления, с другой стороны, это когда предметная область описывается как некоторое, возможно, очень большое, количество одновременных (параллельных) потоков или событий, которые конкурентно взаимодействуют.
Оба этих аспекта достаточно сложны в любом языке, экосистеме и парадигме, и главная проблема - это так называемый нон-детерминизм или неопределённость. Он возникает, когда параллельные вычисления разделяют между собой изменяемое состояние.
var x = 0;
setTimeout(function () { x = x + 1; }, 0);
setTimeout(function () { x = x * 2; }, 0);
console.log(x);
setTimeout(function () { x = x + 1; }, 0);
setTimeout(function () { x = x * 2; }, 0);
console.log(x);
Вот такой весёлый код на джаваскрипте в браузере может вывести и 1, и 2. А если переписать его на новомодных html5 воркерах, то и 0.
Замечаем, однако, что в самом определении проблемы звучит “изменяемое состояние”. Так вот. Функциональное программирование - оно как раз про “избегать изменяемого состояния”. В этой парадигме широко используются иммутабельные структуры данных, а в ортодоксально функциональных языках так вообще запрещают переменные, что приводит к тому, что единственным способом организации цикла является рекурсия.
Именно то, что параллельные вычисления - это реальность и никуда нам от неё не деться, а функциональное программирование, в частности, отказ от изменяемого состояния, сильно облегчает нам борьбу с неопределённостью (нон-детерминизмом), что является основной причиной сложности паралеллизма и конкурентности, и обусловило всевозрастающий интерес к функциональному программированию в последние годы.
При написании кода в функциональной парадигме задача осмысляется и реализуется совсем по-другому, не так, как в императивной. Программист реально по-другому мыслит.
В императивном программировании программист во времени. Инструкции выполняются последовательно, сначала одна, потом другая, и если этот порядок каким-то образом нарушается, то рушится всё.
В функциональном программировании программист думает не так. Он описывает одну часть, вторую, третью строит на их основании, четвёртую - комбинируя какие-то из ранее написанных... Мартин Одерский говорит, что программист мыслит в пространстве, противопоставляя это мышлению во времени.
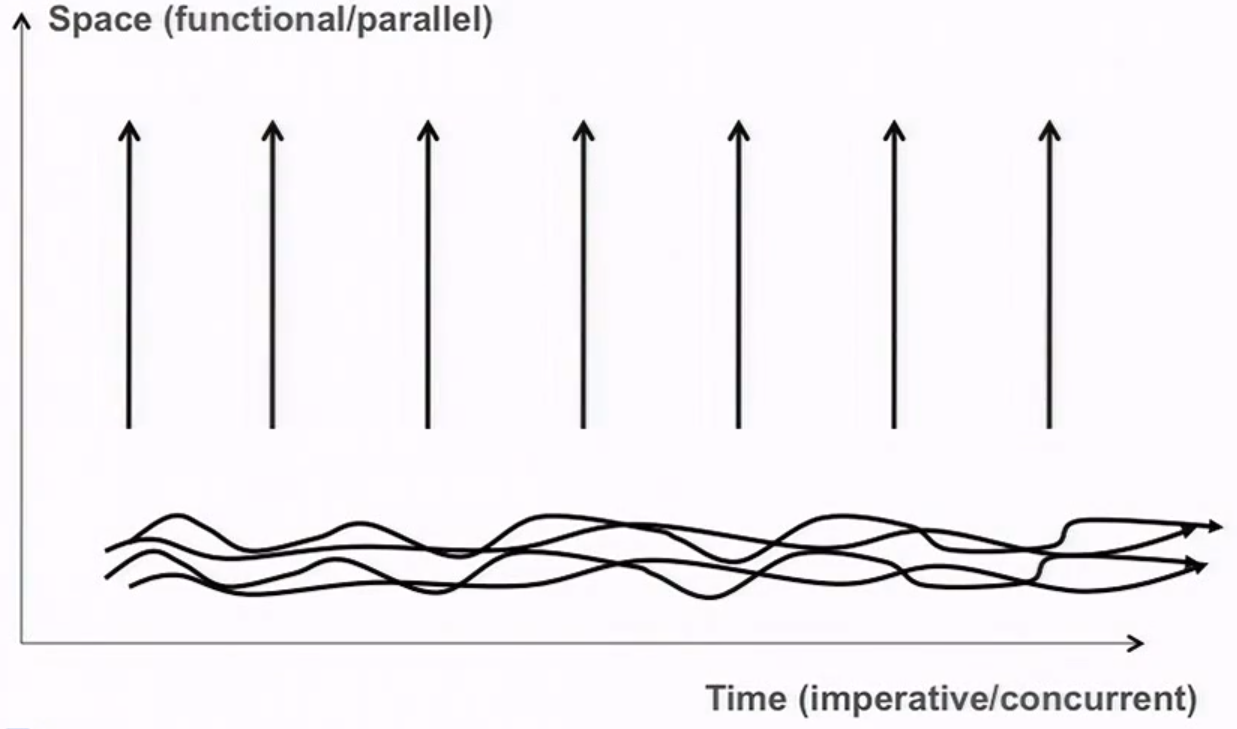
Если добавить параллельности, мыслить в пространстве это не мешает. Никто не занимает место другого. Если мыслить во времени, становится тяжело, потому что всё происходит одновременно, конкурируя за общие ресурсы. Тот самый нон-детерминизм подкрадывается к вам.
Для того, чтобы с этим бороться, программисты придумали блокировки, мьютексы, программную транзакционную память... Всё это работает, но об этом надо постоянно думать, это проникает в код, заполняет его, не являясь решением предметной задачи, а хуже всего то, что это “отрицательный код” - который не решает задачу, а наоборот, придерживает код, который задачу решает, чтобы тот был “поспокойнее”.
А хочется решать задачу.
И вот тут важно понять, что отказ от изменяемого состояния не приводит ни к потере выразительности, ни к потере производительности, ни к потере памяти =)
Сначала мы добавляем иммутабельные коллекции. Т.е., структуры данных, которые невозможно изменить, как невозможно изменить число. Это делает программирование ближе к математике, где, к примеру, точка не может увеличить свою абсциссу и переместиться правее - это будет уже другая точка.
И операция “добавить элемент в список” должна возвращать список, отличающийся от заданного наличием данного элемента.
Если всё иммутабельно, такие структуры данных очень экономно расходуют память, поскольку они копируют только отличающиеся части.
Теперь внимание - если мы ничего не меняем, только создаём новое, то нас не волнует проблема неопределённости. Возьмём императивный код из быстрой сортировки, который делит элементы на большие некоторого значения, и меньшие, и заменим идентификаторы, чтобы он описывал какой-то доменный процесс:
$people = array();$men = array();$women = array();foreach ($people as $person) {
array_push(($person->gender == 'male' ? $men : $women), $person)
}
array_push(($person->gender == 'male' ? $men : $women), $person)
}
Поделим людей на мужчин и женщин.
Давайте возьмём этот же код, написанный в функциональном стиле:
val people: Array[Person]
val (men, women) = people partition (_.gender == "male")
val (men, women) = people partition (_.gender == "male")
Во-первых, он, как это часто бывает с функциональным кодом, ярче выражает свои намерения. Во-вторых, давайте попробуем сделать вычисления параллельными.
Что мы будем делать в случае императивного кода? Разобьём массив на подмассивы, позапускаем потоков, выставим локи, дождёмся результатов через Thread::join... Мы всё ещё останемся с недетерминизмом, потому что массивы $men и $women будут заполняться в случайном порядке, и если нас это вдруг начнёт волновать, придётся бороться ещё и с этим. Потом, не дай Бог, у вас возникнет состояние гонки и вы убъёте как минимум четыре пациента, которых будут лечить аппаратом лучевой терапии с вашим кодом в прошивке. Кому интересно, о чём я, гуглить therac-25. Да, конкурентные вычисления, основанные на потоках, уже убивали невинных пользователей.
А вот в данном конкретном функциональном коде мы допишем к people .par:
val people: Array[Person]
val (men, women) = people.par partition (_.gender == "male")
val (men, women) = people.par partition (_.gender == "male")
Всё. Появится то, что в Скале называют “параллельным массивом” и вычисление пойдёт в несколько потоков, а редукциё соберёт для нас результаты в правильном порядке.
Здесь интересно то, что на параллельных коллекциях не только map, но и reduce параллельный.
val people: Array[Person]
val totalMoney = people.par map (_.money) reduce (_+_)
val totalMoney = people.par map (_.money) reduce (_+_)
Для того, чтобы не было недетерминизма в map достаточно отсутствия побочных эффектов. Для того, чтобы не было недетерминизма в reduce, нужно ещё чтобы переданная туда функция обладала свойством ассоциативности. Скала никак это не проверяет, хотя в серьёзной, мощной и правильной системе типов и это возможно.
Здесь я хочу заметить, что дело не только и не столько в замечательных Скаловских параллельных коллекциях, сколько в том, что изначальный код написан без побочных эффектов и изменяемого состояния, плюс абстрация partition отделена там от условия, по которому partition выполняется, за счёт наличия в языке функций высокого порядка. Это делает возможным подобную лёгкость параллельных вычислений.
Для конкурентных вычислений в Scala есть Akka, и она так же замечательная, как OTP.
actor {
receive {
case people: Set[Person] =>
val (men, women) = people partition (_.gender == 'male')
Cosmopolitan ! women
Playboy ! men
}
}
receive {
case people: Set[Person] =>
val (men, women) = people partition (_.gender == 'male')
Cosmopolitan ! women
Playboy ! men
}
}
Я бы с удовольствием послушал хороший доклад про Акку на одной из следующих конференций.
Есть ещё много радостей в “настоящем” функциональном программировании: функторы, монады, выведение типов, классы типов... Но главное - это переход от “как” к “что”, переход из времени в пространство, отказ от изменяемого состояния, пока получается и абстракция алгоритмов с помощью комбинаторов (map, reduce, filter и другие) и функций высшего порядка.
Пример на практике. Функционального программирования здесь не очень много, но сам подход оттуда.
Есть такой смешной антипаттерн в Ruby on Rails - паутина before_filter’ов. Когда сверху контроллера у вас пять, а то и больше строчек before_filter, у некоторых из которых есть ещё only и except, и вы уже разок фиксили баг, меняя порядок этих строчек. У меня такое было и это жутко.
class OrderController < ApplicationController
before_filter :authenticate_user!
before_filter :load_order, only: [:edit, :update, :destroy]
before_filter :create_order_from_params, only: [:new, :create]
before_filter :authorize_user_on_order!, only: [:edit, :update, :destroy]
before_filter :update_order_from_params, only: [:update]
before_filter :render_if_save_error, only: [:create, :update]
def new; end
def edit; endbefore_filter :authenticate_user!
before_filter :load_order, only: [:edit, :update, :destroy]
before_filter :create_order_from_params, only: [:new, :create]
before_filter :authorize_user_on_order!, only: [:edit, :update, :destroy]
before_filter :update_order_from_params, only: [:update]
before_filter :render_if_save_error, only: [:create, :update]
def new; end
def create
redirect_to success_url
end
def update
redirect_to @order
end
def destroy
@order.destroy
redirect_to success_url
end
private
def load_order
@order = Order.find params[:id]
end
def create_order_from_params
@order = Order.new params[:order]
end
def authorize_user_on_order!
permission_denied! unless current_user.can_edit? @order
end
def update_order_from_params
@order.update_attributes
end
def render_if_save_error
unless @order.valid?
render 'error' and return false
end
end
end
def load_order
@order = Order.find params[:id]
end
def create_order_from_params
@order = Order.new params[:order]
end
def authorize_user_on_order!
permission_denied! unless current_user.can_edit? @order
end
def update_order_from_params
@order.update_attributes
end
def render_if_save_error
unless @order.valid?
render 'error' and return false
end
end
end
Суть тут в том, что все эти фильтры работают с переменными экземпляра контроллера, тем самым, корень наших проблем как обычно в изменяемом состоянии и мышлении во времени. Несмотря на то, что всё очень даже однопоточно, стоит последовательность инструкций разнести по разным местам и спрятать за колбеками, как мы уже теряемся.
Я заменил большую часть этих фильтров просто методами. При входе в action их клубок разматывается совершенно самостоятельно, и я совершенно не забочусь о порядке вычислений.
class OrderController < ApplicationController
before_filter :authenticate_user!
def new
@order = order
end
def create
@order = refreshed_order
@order.save
respond_with(@order)
end
def edit
@order = order
end
def update
@order = refreshed_order
@order.save
respond_with(@order)
end
def destroy
@order = order
@order.destroy
respond_with(@order)
end
private
def order
params[:id] ? ensure_access! Order.find(params[:id]) : Order.new
end
def resfreshed_order
order.tap { |o| o.attributes = params[:order] }
end
def ensure_access!(order)
current_user.can_edit?(order) ? order : permission_denied!
end
end
before_filter :authenticate_user!
def new
@order = order
end
def create
@order = refreshed_order
@order.save
respond_with(@order)
end
def edit
@order = order
end
def update
@order = refreshed_order
@order.save
respond_with(@order)
end
def destroy
@order = order
@order.destroy
respond_with(@order)
end
private
def order
params[:id] ? ensure_access! Order.find(params[:id]) : Order.new
end
def resfreshed_order
order.tap { |o| o.attributes = params[:order] }
end
def ensure_access!(order)
current_user.can_edit?(order) ? order : permission_denied!
end
end
Мне это настолько понравилось, что захотелось вообще не выставлять переменную экземпляра в контроллере, а отдать во вью, да и самому работать, сразу с методом. Стало, на мой взгляд, ещё лучше, хотя здесь меня уже можно упрекнуть в грехе неидиоматичности.
class OrderController < ApplicationController
before_filter :authenticate_user!
helper_method :order
def new; end
def edit; end
def create
order.save
respond_with(order)
end
def update
order.save
respond_with(order)
end
def destroy
order.destroy
respond_with(order)
end
private
def order
@_order ||= refresh(params[:id] ? ensure_access! Order.find(params[:id]) : Order.new)
end
def resfresh(order)
order.tap { |o| o.attributes = params[:order] if params[:order] }
end
def ensure_access!(order)
current_user.can_edit?(order) ? order : permission_denied!
end
end
before_filter :authenticate_user!
helper_method :order
def new; end
def edit; end
def create
order.save
respond_with(order)
end
def update
order.save
respond_with(order)
end
def destroy
order.destroy
respond_with(order)
end
private
def order
@_order ||= refresh(params[:id] ? ensure_access! Order.find(params[:id]) : Order.new)
end
def resfresh(order)
order.tap { |o| o.attributes = params[:order] if params[:order] }
end
def ensure_access!(order)
current_user.can_edit?(order) ? order : permission_denied!
end
end
Тут ещё можно было бы добавить инкапсуляцию мемоизации с помощью некоего decent_exposure, который, впрочем, насколько прост, что его можно реализовать самостоятельно. Всё, что делает expose - это мемоизирует и пишет за вас helper_method.
class OrderController < ApplicationController
before_filter :authenticate_user!
def new; end
def edit; end
def create
order.save
respond_with(order)
end
def update
order.save
respond_with(order)
end
def destroy
order.destroy
respond_with(order)
end
expose(:order) {
refresh(params[:id] ? ensure_access! Order.find(params[:id]) : Order.new)
}
private
def resfresh(order)
order.tap { |o| o.attributes = params[:order] if params[:order] }
end
def ensure_access!(order)
current_user.can_edit?(order) ? order : permission_denied!
end
end
before_filter :authenticate_user!
def new; end
def edit; end
def create
order.save
respond_with(order)
end
def update
order.save
respond_with(order)
end
def destroy
order.destroy
respond_with(order)
end
expose(:order) {
refresh(params[:id] ? ensure_access! Order.find(params[:id]) : Order.new)
}
private
def resfresh(order)
order.tap { |o| o.attributes = params[:order] if params[:order] }
end
def ensure_access!(order)
current_user.can_edit?(order) ? order : permission_denied!
end
end
Выводы:
- От параллельного и конкурентного программирования никому никуда не деться, или его приложения будут сильно проигрывать в скорости исполнения, что вполне может для этих приложений быть фатальным.
- Параллельные и конкурентные вычисления на потоках и блокировках уже убивали людей.
- Функциональное программирование прекрасно само по себе и замечательно решает существенную часть параллельных вычислений.
- Изменяемое состояние - зло, чистые функции - добро. Я готов провозгласить новый смелл “переприсвоение локальной переменной”.
- Пишите чисто.
Ссылки:
1. Вдохновением, парой картинок и общей напраленностью я обязан выступлению Мартина Одерского "Working hard to keep it simple" на конференции O'Reilly OSCON Java 2011.
2. Своим интересом к функциональному программированию я обязан книге Абельсона и Сассмана "Структура и интерпретация компьютерных программ".
3. Своим интересом к языку программирования Scala я обязан курсу "Принципы функционального программирования в Scala" на coursera.
4. Идеей заменить в контроллерах поток вычислений цепочкой вычислений я обязан гему decent_exposure.
5. Другой хороший пример подаёт гем focused_controller.
Комментариев нет:
Отправить комментарий